Omae wa mou shindeiru

AlmightySnoo 🐢🇮🇱🇺🇦
Yoko, Shinobu ni, eto… 🤔
עַם יִשְׂרָאֵל חַי Slava Ukraini 🇺🇦 ❤️ 🇮🇱
- 20 Posts
- 102 Comments
Joined 1 year ago
Cake day: June 14th, 2023
You are not logged in. If you use a Fediverse account that is able to follow users, you can follow this user.

 41·5 months ago
41·5 months agoYeah it’s not Linux. It’s forked off MenuetOS (https://menuetos.net/ ) which is a hobby OS written entirely in assembly (FASM flavor, https://flatassembler.net/ ).
It’s actually a good thing that visual learners get a chance to learn useful stuff by watching videos. Not everyone has the attention span required to read through a Wikipedia page.

For anyone wondering what Proton GE is, it’s Proton on steroids: https://github.com/GloriousEggroll/proton-ge-custom
For instance, even if you have an old Intel integrated GPU, chances are you can still benefit from AMD’s FSR just by pushing a few flags to Proton GE, even if the game doesn’t officially support it, and you’ll literally get a free FPS boost (tested it for fun and can confirm on an Intel UHD Graphics 620).
 181·6 months ago
181·6 months agoCongrats! Your laptop will be even happier with a lighter but still nice-looking desktop environment like Xfce and you even have an Ubuntu flavor around it: Xubuntu.
Hard to tell as it’s really dependent on your use. I’m mostly writing my own kernels (so, as if you’re doing CUDA basically), and doing “scientific ML” (SciML) stuff that doesn’t need anything beyond doing backprop on stuff with matrix multiplications and elementwise nonlinearities and some convolutions, and so far everything works. If you want some specific simple examples from computer vision: ResNet18 and VGG19 work fine.
Works out of the box on my laptop (the
exportbelow is to force ROCm to accept my APU since it’s not officially supported yet, but the 7900XTX should have official support):
Last year only compiling and running your own kernels with
hipccworked on this same laptop, the AMD devs are really doing god’s work here.
Yup, it’s definitely about the “open-source” part. That’s in contrast with Nvidia’s ecosystem: CUDA and the drivers are proprietary, and the drivers’ EULA prohibit you from using your gaming GPU for datacenter uses.
ROCm is that its very unstable
That’s true, but ROCm does get better very quickly. Before last summer it was impossible for me to compile and run HIP code on my laptop, and then after one magic update everything worked. I can’t speak for rendering as that’s not my field, but I’ve done plenty of computational code with HIP and the performance was really good.
But my point was more about coding in HIP, not really about using stuff other people made with HIP. If you write your code with HIP in mind from the start, the results are usually good and you get good intuition about the hardware differences (warps for instance are of size 32 on NVidia but can be 32 or 64 on AMD and that makes a difference if your code makes use of warp intrinsics). If however you just use AMD’s CUDA-to-HIP porting tool, then yeah chances are things won’t work on the first run and you need to refine by hand, starting with all the implicit assumptions you made about how the NVidia hardware works.
HIP is amazing. For everyone saying “nah it can’t be the same, CUDA rulez”, just try it, it works on NVidia GPUs too (there are basically macros and stuff that remap everything to CUDA API calls) so if you code for HIP you’re basically targetting at least two GPU vendors. ROCm is the only framework that allows me to do GPGPU programming in CUDA style on a thin laptop sporting an AMD APU while still enjoying 6 to 8 hours of battery life when I don’t do GPU stuff. With CUDA, in terms of mobility, the only choices you get are a beefy and expensive gaming laptop with a pathetic battery life and heating issues, or a light laptop + SSHing into a server with an NVidia GPU.
They’re worse than us Arch users (btw)

That’s a good way of maximizing technical debt.
 471·7 months ago
471·7 months agoThe court documents state that Brody’s employment was terminated after he violated company policies by connecting a USB drive containing pornography to company computers.
Okay, I mean, there are many types of stupid but that’s a completely new one.
The OS won’t matter much in the beginning, though it helps that you’re already using Linux as you likely already have Python and GCC installed.
I don’t think you need a better PC than what you already have if the only goal is to learn programming, so I’d spend that money on something else.
I’d suggest you go through Harvard’s CS50 if you’ve never been exposed to computer science before: https://www.harvardonline.harvard.edu/course/cs50-introduction-computer-science . You can audit it for free, you don’t really need to pay for the certificate (which IMO doesn’t have much value at that level anyway).
Also, try to get into a computer science degree if you want to do that as a career, bootcamps and MOOCs are nice additions but will never replace a real degree.
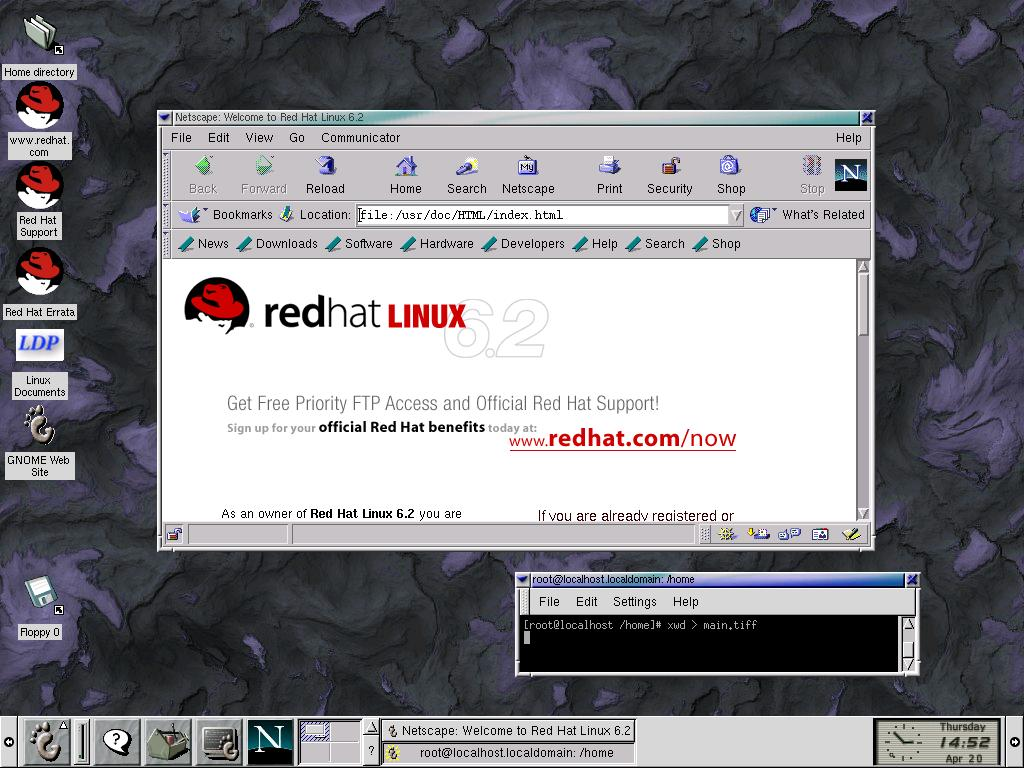
I was learning C/C++ back then and although the nostalgia is strong with this one, Turbo C++ was obviously shit (and Borland quickly killed it later anyway), and while looking around for alternatives I found DJGPP which introduced me to the GNU toolchain and so the jump to Linux to have all of that natively instead of running on DOS was very natural. My very first distro was Redhat Linux 6.2 that I got as a free CD along with a magazine (also got a Corel Linux CD the same way that I was excited about given how their WordPerfect was all the rage back then but I was never able to install it, I don’t remember what the issue was) and it looked like this (screenshot from https://everythinglinux.org/redhat62/index.html ):
Roughly one year. No GPU code however for that project as the target library is CPU-only anyway so not really comparable to PyTorch (and PyTorch is more than just the autodiff), but there was lots of SIMD vectorization. Yeah you could train a neural network on CPU with it if you want, and the expression template stuff I talked about would be somewhat equivalent to PyTorch’s operator fusion, but the target use is more quant finance code.
Automatic differentiation in C++17, had to do it from scratch as they weren’t open to 3rd-party libraries and it had to integrate with many symbolic calculations that are also done in the library (so even if you used a 3rd-party library you’d still have to rewrite parts of it to deal with the symbolic stuff). Succeeded in doing it and basically the performance was on par with what people in the industry would expect (all derivatives at once in around 3 times the evaluation time, sometimes much less if the calculation code has no dynamic parts and is differentiated entirely at compile-time).
It was pretty cool because it was a fun opportunity to really abuse template meta-programming and especially expression templates (you’re basically sort of building expression trees at compile-time), compile-time lazy evaluation, static polymorphism and lots of SFINAE dark magic and play around with custom memory allocators.
Then you get scolded by the CI guys because your template nightmare makes the build times 3x slower, so the project then also becomes an occasion to try out a bunch of tricks to speed up compilation.
Ubuntu used to ship free CDs too: https://commons.wikimedia.org/wiki/File:Ubuntu_10.04_CDs.jpg
They stopped doing that in 2011.
 241·8 months ago
241·8 months agoCopied from miku-chan03?
it’s actually the opposite, MikuChan03 was created one month after this: https://github.com/Xerasin/GCinemaCraftDownloader/issues/1



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
for the math homies, you could say that NaN is an absorbing element